Striping (RAID-0)
Striping (RAID-0) is useful if you need large amounts of data written to or read from physical disks, and performance is important. Striping is also helpful in balancing the I/O load from multi-user applications across multiple disks. By using parallel data transfer to and from multiple disks, striping significantly improves data-access performance.Striping maps data so that the data is interleaved among two or more physical disks. A striped plex contains two or more subdisks, spread out over two or more physical disks. Data is allocated alternately and evenly to the subdisks of a striped plex.
The subdisks are grouped into "columns," with each physical disk limited to one column. Each column contains one or more subdisks and can be derived from one or more physical disks. The number and sizes of subdisks per column can vary. Additional subdisks can be added to columns, as necessary.
Warning: Striping a volume, or splitting a volume across multiple disks, increases the chance that a disk failure will result in failure of that volume.
If five volumes are striped across the same five disks, then failure of any one of the five disks will require that all five volumes be restored from a backup. If each volume is on a separate disk, only one volume has to be restored. (As an alternative to striping, use mirroring or RAID-5 to substantially reduce the chance that a single disk failure results in failure of a large number of volumes.) Data is allocated in equal-sized stripe units that are interleaved between the columns. Each stripe unit is a set of contiguous blocks on a disk. The default stripe unit size is 64 kilobytes.
Striping across three columns shows an example with three columns in a striped plex, six stripe units, and data striped over the three columns.
Striping across three columns

A stripe consists of the set of stripe units at the same positions across all columns. In the figure, stripe units 1, 2, and 3 constitute a single stripe.
Viewed in sequence, the first stripe consists of:
The second stripe consists of:
Striping continues for the length of the columns (if all columns are the same length), or until the end of the shortest column is reached. Any space remaining at the end of subdisks in longer columns becomes unused space.
Example of a striped plex with one subdisk per column shows a striped plex with three equal sized, single-subdisk columns.
Example of a striped plex with one subdisk per column
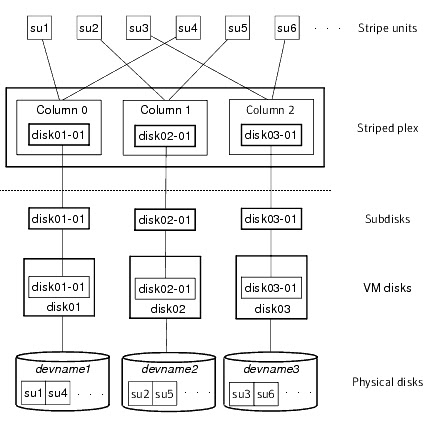
There is one column per physical disk. This example shows three subdisks that occupy all of the space on the VM disks. It is also possible for each subdisk in a striped plex to occupy only a portion of the VM disk, which leaves free space for other disk management tasks.
Example of a striped plex with concatenated subdisks per column shows a striped plex with three columns containing subdisks of different sizes.
Example of a striped plex with concatenated subdisks per column

Each column contains a different number of subdisks. There is one column per physical disk. Striped plexes can be created by using a single subdisk from each of the VM disks being striped across. It is also possible to allocate space from different regions of the same disk or from another disk (for example, if the size of the plex is increased). Columns can also contain subdisks from different VM disks.
Mirroring (RAID-1)
Mirroring uses multiple mirrors (plexes) to duplicate the information contained in a volume. In the event of a physical disk failure, the plex on the failed disk becomes unavailable, but the system continues to operate using the unaffected mirrors.Although a volume can have a single plex, at least two plexes are required to provide redundancy of data. Each of these plexes must contain disk space from different disks to achieve redundancy.
When striping or spanning across a large number of disks, failure of any one of those disks can make the entire plex unusable. Because the likelihood of one out of several disks failing is reasonably high, you should consider mirroring to improve the reliability (and availability) of a striped or spanned volume.
Disk duplexing, in which each mirror exists on a separate controller, is also supported.
Creating a mirrored volume
A mirrored volume provides data redundancy by containing more than one copy of its data. Each copy (or mirror) is stored on different disks from the original copy of the volume and from other mirrors. Mirroring a volume ensures that its data is not lost if a disk in one of its component mirrors fails.A mirrored volume requires space to be available on at least as many disks in the disk group as the number of mirrors in the volume.
To create a new mirrored volume, use the following command:
#
vxassist [-b] [-g diskgroup] make volume length \ layout=mirror [nmirror=number] [init=active] Specify the
-b option if you want to make the volume immediately available for use. For example, to create the mirrored volume,
volmir, in the disk group, mydg, use the following command: #
vxassist -b -g mydg make volmir 5g layout=mirror To create a volume with 3 instead of the default of 2 mirrors, modify the command to read:
#
vxassist -b -g mydg make volmir 5g layout=mirror nmirror=3 Mirroring across targets, controllers or enclosures
To create a volume whose mirrored data plexes lie on different controllers (also known as disk duplexing) or in different enclosures, use thevxassist command as described in this section. In the following command, the attribute
mirror=target specifies that volumes should be mirrored between identical target IDs on different controllers. #
vxassist [-b] [-g diskgroup] make volume length \ layout=layout mirror=target [attributes] Specify the
-b option if you want to make the volume immediately available for use. The attribute
mirror=ctlr specifies that disks in one mirror should not be on the same controller as disks in other mirrors within the same volume: #
vxassist [-b] [-g diskgroup] make volume length \ layout=layout mirror=ctlr [attributes] Note Both paths of an active/passive array are not considered to be on different controllers when mirroring across controllers.
The following command creates a mirrored volume with two data plexes in the disk group,
mydg: #
vxassist -b -g mydg make volspec 10g layout=mirror nmirror=2 \ mirror=ctlr ctlr:scsi2 ctlr:scsi3 The disks in one data plex are all attached to controller
scsi2, and the disks in the other data plex are all attached to controller scsi3. This arrangement ensures continued availability of the volume should either controller fail. The attribute
mirror=enclr specifies that disks in one mirror should not be in the same enclosure as disks in other mirrors within the same volume. The following command creates a mirrored volume with two data plexes:
#
vxassist -b make -g mydg volspec 10g layout=mirror nmirror=2 \ mirror=enclr enclr:enc1 enclr:enc2 The disks in one data plex are all taken from enclosure
enc1, and the disks in the other data plex are all taken from enclosure enc2. This arrangement ensures continued availability of the volume should either enclosure become unavailable. There are other ways in which you can control how volumes are laid out on the specified storage.
Striping plus mirroring (mirrored-stripe or RAID-0+1)
VxVM supports the combination of mirroring above striping. The combined layout is called a mirrored-stripe layout. A mirrored-stripe layout offers the dual benefits of striping to spread data across multiple disks, while mirroring provides redundancy of data.For mirroring above striping to be effective, the striped plex and its mirrors must be allocated from separate disks.
Mirrored-stripe volume laid out on six disks shows an example where two plexes, each striped across three disks, are attached as mirrors to the same volume to create a mirrored-stripe volume.

The layout type of the data plexes in a mirror can be concatenated or striped. Even if only one is striped, the volume is still termed a mirrored-stripe volume. If they are all concatenated, the volume is termed a mirrored-concatenated volume.
Mirroring plus striping (striped-mirror, RAID-1+0 or RAID-10)
VxVM supports the combination of striping above mirroring. This combined layout is called a striped-mirror layout. Putting mirroring below striping mirrors each column of the stripe. If there are multiple subdisks per column, each subdisk can be mirrored individually instead of each column.A striped-mirror volume is an example of a layered volume.
Layered volumes
A layered volume is a virtual Veritas Volume Manager object that is built on top of other volumes. The layered volume structure tolerates failure better and has greater redundancy than the standard volume structure. For example, in a striped-mirror layered volume, each mirror (plex) covers a smaller area of storage space, so recovery is quicker than with a standard mirrored volume.Example of a striped-mirror layered volume shows a typical striped-mirror layered volume where each column is represented by a subdisk that is built from an underlying mirrored volume.
Example of a striped-mirror layered volume

The volume and striped plex in the "Managed by User" area allow you to perform normal tasks in VxVM. User tasks can be performed only on the top-level volume of a layered volume.
Underlying volumes in the "Managed by VxVM" area are used exclusively by VxVM and are not designed for user manipulation. You cannot detach a layered volume or perform any other operation on the underlying volumes by manipulating the internal structure. You can perform all necessary operations in the "Managed by User" area that includes the top-level volume and striped plex (for example, resizing the volume, changing the column width, or adding a column).
System administrators can manipulate the layered volume structure for troubleshooting or other operations (for example, to place data on specific disks). Layered volumes are used by VxVM to perform the following tasks and operations:
As for a mirrored-stripe volume, a striped-mirror volume offers the dual benefits of striping to spread data across multiple disks, while mirroring provides redundancy of data. In addition, it enhances redundancy, and reduces recovery time after disk failure.
Striped-mirror volume laid out on six disks shows an example where a striped-mirror volume is created by using each of three existing 2-disk mirrored volumes to form a separate column within a striped plex.
Striped-mirror volume laid out on six disks


Compared to mirrored-stripe volumes, striped-mirror volumes are more tolerant of disk failure, and recovery time is shorter.
If the layered volume concatenates instead of striping the underlying mirrored volumes, the volume is termed a concatenated-mirror volume.
RAID-5 (striping with parity)
Although both mirroring (RAID-1) and RAID-5 provide redundancy of data, they use different methods. Mirroring provides data redundancy by maintaining multiple complete copies of the data in a volume. Data being written to a mirrored volume is reflected in all copies. If a portion of a mirrored volume fails, the system continues to use the other copies of the data.RAID-5 provides data redundancy by using parity. Parity is a calculated value used to reconstruct data after a failure. While data is being written to a RAID-5 volume, parity is calculated by doing an exclusive OR (XOR) procedure on the data. The resulting parity is then written to the volume. The data and calculated parity are contained in a plex that is "striped" across multiple disks. If a portion of a RAID-5 volume fails, the data that was on that portion of the failed volume can be recreated from the remaining data and parity information. It is also possible to mix concatenation and striping in the layout.
Parity locations in a RAID-5 mode shows parity locations in a RAID-5 array configuration.

RAID-5 volumes can additionally perform logging to minimize recovery time. RAID-5 volumes use RAID-5 logs to keep a copy of the data and parity currently being written. RAID-5 logging is optional and can be created along with RAID-5 volumes or added later.
Traditional RAID-5 arrays
A traditional RAID-5 array is several disks organized in rows and columns. A column is a number of disks located in the same ordinal position in the array. A row is the minimal number of disks necessary to support the full width of a parity stripe.Traditional RAID-5 array shows the row and column arrangement of a traditional RAID-5 array.
Traditional RAID-5 array

This traditional array structure supports growth by adding more rows per column. Striping is accomplished by applying the first stripe across the disks in Row 0, then the second stripe across the disks in Row 1, then the third stripe across the Row 0 disks, and so on. This type of array requires all disks columns, and rows to be of equal size.
Snapshot technology is becoming prevalent to perform data protection and other tasks such as data mining and data cloning. Most leading storage hardware and software vendors provide snapshot support. Advanced data protection solutions like IBM® Tivoli® Storage Manager are being built based on the snapshot technology. Use of snapshot technology for data protection offers critical business value, such as zero impact backup with minimal or no application downtime, frequent backups (for example, hourly) to reduce recovery time, efficient backup of large volumes of data, reduced exposure to data loss, and instant recovery from snapshot. However, you must give careful consideration before selecting a solution that fits your needs and environment.
The goal of this series is to provide an overview of snapshot technology and the snapshot-based data protection solutions.
Snapshot is a common industry term denoting the ability to record the state of a storage device at any given moment and preserve that snapshot as a guide for restoring the storage device in the event that it fails. A snapshot primarily creates a point-in-time copy of the data. Typically, snapshot copy is done instantly and made available for use by other applications such as data protection, data analysis and reporting, and data replication applications. The original copy of the data continues to be available to the applications without interruption, while the snapshot copy is used to perform other functions on the data.
Snapshots provide an excellent means of data protection. The trend towards using snapshot technology comes from the benefits that snapshots deliver in addressing many of the issues that businesses face. Snapshots enable better application availability, faster recovery, easier back up management of large volumes of data, reduces exposure to data loss, virtual elimination of backup windows, and lowers total cost of ownership.
This section describes commonly used methodologies for creating the snapshot.
Before a write is allowed to a block, copy-on-write moves the original data block to the snapshot storage. This keeps the snapshot data consistent with the exact time the snapshot was taken. Read requests to the snapshot volume of the unchanged data blocks are redirected to the original volume, while read requests to data blocks that have been changed are directed to the "copied" blocks in the snapshot. Snapshot contains the meta-data that describes the data blocks that have changed since the snapshot was first created. Note that original data blocks are copied only once into the snapshot storage when the first write request is received.
The following diagram illustrates a snapshot operation that creates a logical copy of the data using copy-on-write method.
Figure 1. Copy-on-write illustration

Copy-on-write snapshot might initially impact performance on the original volume while it exists, because write requests to the original volume must wait while original data is being "copied out" to the snapshot. The read requests to snapshot are satisfied from the original volumes if data being read hasn’t changed. However, this method is highly space efficient, because the storage required to create a snapshot is minimal to hold only the data that is changing. Additionally, the snapshot requires original copy of the data to be valid.
New writes to the original volume are redirected to another location set aside for snapshot. The advantage of redirecting the write is that only one write takes place, whereas with copy-on-write, two writes occur (one to copy original data onto the storage space, the other to copy changed data).
However, with redirect-on-write, the original copy contains the point-in-time data, that is, snapshot, and the changed data reside on the snapshot storage. When a snapshot is deleted, the data from the snapshot storage must be reconciled back into the original volume. Furthermore, as multiple snapshots are created, access to the original data, tracking of the data in snapshots and original volume, and reconciliation upon snapshot deletion is further complicated . The snapshot relies on the original copy of the data and the original data set can quickly become fragmented.
EMC Symmterix and AIX Logical Volume Manager support split mirror. Additionally, any raid system supporting multiple mirrors can be used to create a clone by splitting a mirror.
Snapshot technology overview
The goal of this series is to provide an overview of snapshot technology and the snapshot-based data protection solutions.
What is a snapshot?
Snapshot is a common industry term denoting the ability to record the state of a storage device at any given moment and preserve that snapshot as a guide for restoring the storage device in the event that it fails. A snapshot primarily creates a point-in-time copy of the data. Typically, snapshot copy is done instantly and made available for use by other applications such as data protection, data analysis and reporting, and data replication applications. The original copy of the data continues to be available to the applications without interruption, while the snapshot copy is used to perform other functions on the data.
Snapshots provide an excellent means of data protection. The trend towards using snapshot technology comes from the benefits that snapshots deliver in addressing many of the issues that businesses face. Snapshots enable better application availability, faster recovery, easier back up management of large volumes of data, reduces exposure to data loss, virtual elimination of backup windows, and lowers total cost of ownership.
How snapshots are implemented
There are different implementation approaches adopted by vendors to create snapshots, each with its own benefits and drawbacks. Therefore, it is important to understand snapshot implementations in order to be able to build effective data protection solutions and identify which functions are most critical for your organization to help select the snapshot vendor accordingly.This section describes commonly used methodologies for creating the snapshot.
Copy-on-write
A snapshot of a storage volume is created using the pre-designated space for the snapshot. When the snapshot is first created, only the meta-data about where original data is stored is copied. No physical copy of the data is done at the time the snapshot is created. Therefore, the creation of the snapshot is almost instantaneous. The snapshot copy then tracks the changing blocks on the original volume as writes to the original volume are performed. The original data that is being written to is copied into the designated storage pool that is set aside for the snapshot before original data is overwritten, hence the name "copy-on-write".Before a write is allowed to a block, copy-on-write moves the original data block to the snapshot storage. This keeps the snapshot data consistent with the exact time the snapshot was taken. Read requests to the snapshot volume of the unchanged data blocks are redirected to the original volume, while read requests to data blocks that have been changed are directed to the "copied" blocks in the snapshot. Snapshot contains the meta-data that describes the data blocks that have changed since the snapshot was first created. Note that original data blocks are copied only once into the snapshot storage when the first write request is received.
The following diagram illustrates a snapshot operation that creates a logical copy of the data using copy-on-write method.
Figure 1. Copy-on-write illustration
Copy-on-write snapshot might initially impact performance on the original volume while it exists, because write requests to the original volume must wait while original data is being "copied out" to the snapshot. The read requests to snapshot are satisfied from the original volumes if data being read hasn’t changed. However, this method is highly space efficient, because the storage required to create a snapshot is minimal to hold only the data that is changing. Additionally, the snapshot requires original copy of the data to be valid.
Redirect-on-write
This method is quite similar to copy-on-write, without the double write penalty, and it offers offers storage space and performance efficient snapshots.New writes to the original volume are redirected to another location set aside for snapshot. The advantage of redirecting the write is that only one write takes place, whereas with copy-on-write, two writes occur (one to copy original data onto the storage space, the other to copy changed data).
However, with redirect-on-write, the original copy contains the point-in-time data, that is, snapshot, and the changed data reside on the snapshot storage. When a snapshot is deleted, the data from the snapshot storage must be reconciled back into the original volume. Furthermore, as multiple snapshots are created, access to the original data, tracking of the data in snapshots and original volume, and reconciliation upon snapshot deletion is further complicated . The snapshot relies on the original copy of the data and the original data set can quickly become fragmented.
Split mirror
Split mirror creates a physical clone of the storage entity, such as the file-system, volume, or LUN for which snapshot is being created, onto another entity of the same kind and the exact same size. The entire contents of the original volume are copied onto a separate volume. Clone copies are highly available, since they are exact duplicates of the original volume that resides on a separate storage space. However, due to the data copy, such snapshots cannot be created instantaneously. Alternatively, a clone can also be made available instantaneously by "splitting" a pre-existing mirror of the volume into two, with the side effect that original volume has one fewer synchronized mirror. This snapshot method requires as much storage space as the original data for each snapshot. This method has the performance overhead of writing synchronously to the mirror copy.EMC Symmterix and AIX Logical Volume Manager support split mirror. Additionally, any raid system supporting multiple mirrors can be used to create a clone by splitting a mirror.